What is the right amount of swap space?
What is the right amount of swap space?
Many years ago, the rule of thumb for the amount of swap space that should be allot on the hard drive was 2X the amount of RAM installed in the computer (of course, that was when more computers' RAM was measured in KB or MB). Therefore, if the computer has 64 kb of RAM, 128 kb swap partition will be the optimum size.This rule took into account the facts that RAM sizes were generally quite small at that time and that allocating more than 2X RAM for swap space did not boost performance. With more than twice RAM for swap, most systems spent more time thrashing than absolutely performing useful work.
RAM has become an reasonable commodity and most computers these days have amounts of RAM that boost into tens of gigabytes. Most of the new users have at least 8GB to 32GB of RAM, my main workstation has 64 GB.
When dealing with computers having big amounts of RAM, the reduce performance factor for swap space is far lower than the 2X multiplier. The Fedora 28 online Installation counselor, which can be found online at Fedora Installation Guide, defines current reasoning about swap space allocation. I have added below any analysis and the table of recommendations from that document.
The following table add the recommended size of a swap partition depending on the amount of in your system and whether you want enough memory for your system to hibernate. The recommended swap partition size is established naturally during installation. To allow for hibernation, however, you will want to compile the swap space in the custom partitioning stage.
Table 1: Fedora 28 documentation system requirements for swap space
Amount of system RAM
|
Recommended swap space
|
Recommended swap with hibernation
|
less than 2 GB
|
2 times the amount of RAM
|
3 times the amount of RAM
|
2 GB - 8 GB
|
Equal to the amount of RAM
|
2 times the amount of RAM
|
8 GB - 64 GB
|
0.5 times the amount of RAM
|
1.5 times the amount of RAM
|
more than 64 GB
|
workload dependent
|
hibernation not recommended
|
At the border between each field listed above (for example, a system with 2 GB, 8 GB, or 64 GB of system RAM), use attention with regard to chosen swap space and hibernation support. If your system resources grant for it, developing the swap space may lead to best performance.
Of course, more Linux administrators have their own concept about the applicable amount of swap space—as well as elegant much everything else. Table 2, below, contains my recommendations based on my particular experiences in different environments. These may not task for you, but as with Table 1, they may help you get started.
Table 2: Recommended system swap space per the author
Amount of RAM
|
Recommended swap space
|
≤ 2GB
|
2X RAM
|
2GB – 8GB
|
= RAM
|
>8GB
|
8GB
|
One discussion of these two tables is that adding more swap space instead of a point will also cause fatigue before filling the swap space due to the amount of RAM being developed.
If you have very little virtual memory following these recommendations, you should add as much RAM as possible instead of more swap space. Use the most appropriate environment for you, all recommendations will affect system performance.Based on the conditions of the Linux environment, it takes time and effort to experiment and make changes.
Adding non-LVM disk environment for more swap space
Since the swap space requirements on a host where Linux is installed, it may be necessary to modify the amount of swap space defined for the system.This process can be used for any common case where you need to increase the amount of swap space. It assumes that there is enough free disk space. This process also assumes that the disk is divided into "raw" EXT4 and the partition is swapped and does not use logical volume management (LVM).
The basic steps to take are simple:
- Turn off the existing swap space.
- Creating a new swap partition
- Reread the partition table.
- Configure the partition as swap space.
- Add the new partition/etc/fstab.
- Turn on swap.
A reboot should not be necessary.
For security reasons, at least make sure that no applications are running and no swap space is used before the exchange. The free or highest order can tell you if the swap space is in use. For added security, you can return to run level 1 or single user mode.
To close all swap space, swap off swap partitions with a command partition:
swapoff -a
Now shows the current partition on the hard drive.
fdisk -l
This will display the current partition table on each drive. Current swap is recognized by partition number.
Start fdisk in interactive mode with the command:
fdisk /dev/<device name>
For example:
fdisk /dev/sda
At this point, fdisk is now interactive and will work only on specified disk drives.
To create a new swap partition, use the fdisk p subcommand to verify enough free space on the disk. The location on the hard drive is displayed in the 512-byte block and the cylinder number starts and ends, so you may need to do some calculation to determine the available space between and between the allocated partition.
Create a new swap partition with n subcommands. Fdisk will ask you the initial cylinder. By default, it selects the minimum number of available cylinders. If you want to change it, type the number of initial cylinders.
The Fdisk command now allows you to enter the partition size in a variety of formats, including the final format number or byte, KB or MB size. Enter 4000 M, which will provide approximately 4 GB of space on the new partition (for example) and press Enter.
To verify that the partition was created as specified, use the p subcommand. Note that the partition can not be exactly as you have specified unless you use the last cylinder number. The Fdisk command can allocate disk space to the entire cylinder, so your division may be smaller or larger than your specified. If the partition is not what you want, you can remove it and make it again.
Now you need to specify that the new partition is a swap partition. The subcommand T allows you to specify the type of partition. Then type T to specify the partition number. For hex code partition you can type, type 82, for the Linux swap partition type, and press Enter.
If you are satisfied with the partition created, use the w sub-command to write a new partition table on the disk. After completing the compilation of the modified partition table, the fdisk program will exit and return to the command prompt. When fdisk terminates writing a new partition table, you may receive the following message:
The partition table has been altered!
Calling ioctl() to re-read partition table.
The kernel still uses the old table.
In the next reboot, the new table will be used.
Syncing disks.
At this point, you use the partprobe command to force the kernel to read the partition table again so that you don't need to reboot.
partprobe
Now use the fdisk -l command to list the partitions. The new swap partition should be the partition listed. Make sure the new partition type is "Linux swap".
It is necessary to modify the /etc/fstab file to point to the new swap partition. The current line might look like this:
LABEL=SWAP-sdaX swap swap defaults 0 0
Where x is the partition number. Add a new line based on the location of the new swap partition that looks similar:
/dev/sdaY swap swap defaults 0 0
Be sure to use the correct partition number. Now you can perform the final step of creating a swap partition. Use the mkswap command to define a partition as a swap partition.
mkswap /dev/sdaY
Using the command the final step is to turn on swap:
swapon -a
Your new swap partition is now online with a pre-existing swap partition. You can verify it using free or top command.
Adding swap to an LVM disk environment
If your disk settings use LVM, it will be easier to change the swap space. Again, it assumes that space is available in the volume group in which the current swap volume is located. By default, the Fedora Linux installation process in an LVM environment makes the swap partition a logical volume. This is easy to do because you can easily increase the size of the swap volume.
Here are the steps needed to increase the amount of swap space in LVM environments:
- Turn off all swap.
- The size of the logical volume designated can be increased for swap.
- Configure the resized volume as swap space.
- Turn on swap.
Let’s first verify that swap exists and a logical volume using the lvs command (list logical volume).
You can see that the current exchange size is 8 GB. In t his case, adding 2 GB to this swap volume will help. First of all, stop the current swap. If you are using swap space, you may have to end an ongoing program.
his case, adding 2 GB to this swap volume will help. First of all, stop the current swap. If you are using swap space, you may have to end an ongoing program.
his case, adding 2 GB to this swap volume will help. First of all, stop the current swap. If you are using swap space, you may have to end an ongoing program.
swapoff -a
Now increase the size of the logical volume.

to make this entire 10GB partition into swap space run the mkswap command
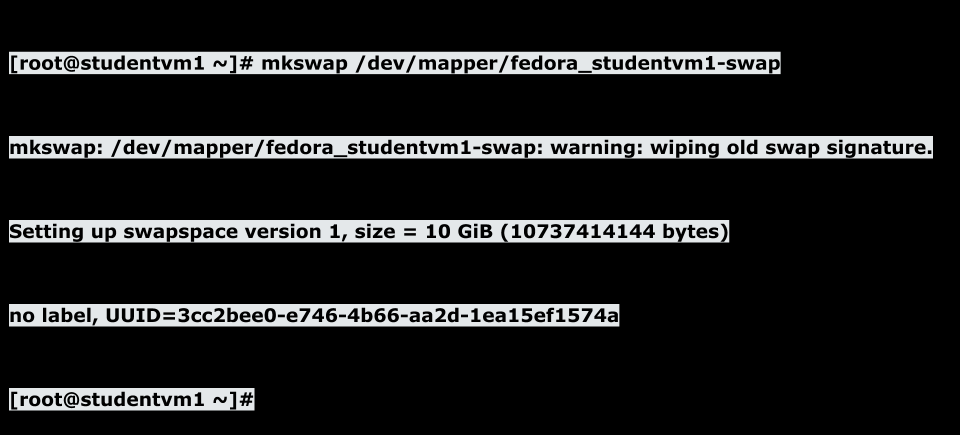
Turn swap back on.
[root@studentvm1 ~]# swapon -a
[root@studentvm1 ~]#
Now use the list block device command to verify that the new swap space exists. Again, there is no need to reboot.

For verification a user can also use the swapon -s command, or top, free, or any of several other commands that are available.
Please note that the inputs of device-specific files are displayed or required in different commands. There are several ways to access a specific device in the / dev directory. My article "Management Tools in Linux" has more information about the / dev directory and its contents.
Related article:Introduction to swap space









